A4-2 医薬関連情報データベースの構築・公開とVaProSの高度化
医薬関連各種データベースの構築と統合、ならびにその利用に関する支援
[1] 支援担当者
| 所属 | ①東京大学 大学院農学生命科学研究科食の安全研究センター | |
|---|---|---|
| 氏名 | ①田之倉 優 | |
| AMED 事業 |
ユニット/領域名 課題名 |
プラットフォーム機能最適化ユニット 創薬等ライフサイエンス研究を促進する研究支援とデータサイエンス |
| 代表機関 代表者 |
東京大学 田之倉 優 |
|
| 支援技術のキーワード | 医薬関連データベース | |
[2] 支援技術の概要
医薬関連情報データベースの構築・公開とVaProSの高度化
[3] 支援技術の利用例
- VaProSによるタンパク質可溶化データベースREFOLDdbの利用 (Mizutani et al. BMC Structural Biology, 17:4 (2017))
- 医食同源老化関連データベースの利用 (Kwon et al. PLOS ONE 12:e0183534 (2017))
- 特定の疾病に対する関連薬抽出ならびに新たな関連薬の推定(ドラッグリポジショニング)
- 各種関連性の推定
[4] 支援担当者の研究概要
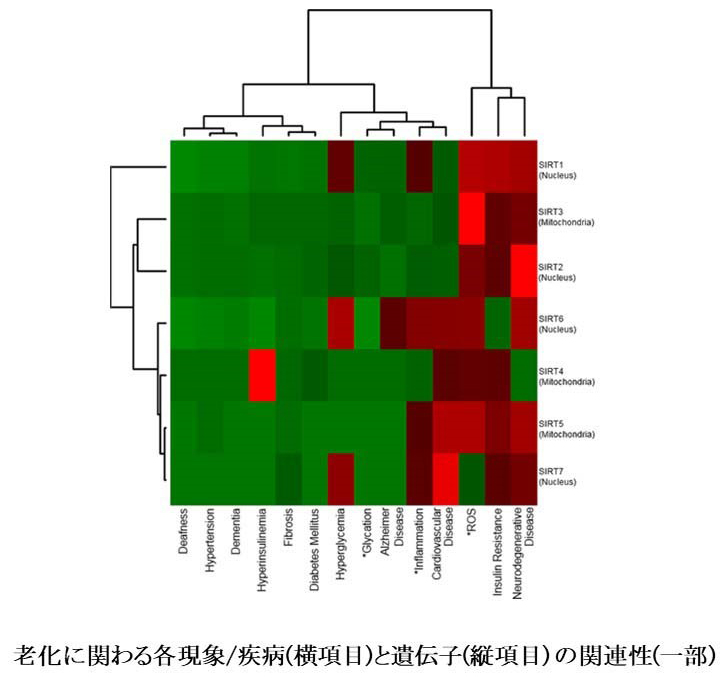
これまでに、データサイエンス研究として、タンパク質リフォールディングデータベースではタンパク質のリフォールディングに関する文献情報を網羅し、老化データベースでは、老化関連用語の選定および、全てのPubMedエントリーについて老化関連用語と遺伝名との各アブストラクト内での共起を調べることにより、それらの関連性を明らかにした(図)。さらに、これらの手法を疾病と関連性検索手法に発展させ、疾病と薬の報告のある関連性のみならず、新たな関連性の推定をも行うことができるようにした。この手法の特徴は、生体物質、遺伝子、タンパク質、代謝反応などのデータベースであるKEGGデータベースから検索語を作成し、PubMedアブストラクト中での各検索語の共起関係をKEGGコード間の関連性に変換、これらの関連性をつなぎ合わせることにより、未だ報告のない関連性をも推定できるようにしたことにある。最終的な目的が疾病―薬関連性であったとしても、検索語を全てのKEGGコードから作成することにより、例えば、タンパク質を介した関連性をも推定できるようになっている。検索の際には英文の処理として必要なステマーを医学・生命科学に対応するように独自に開発するなどの工夫も行った。この検索・推定システムについては、PubMed、KEGGの最新版に対応すべくアップデートを常に行っている。そして、その重要な応用例として、COVID-19に対する関連薬(治療薬等)推定データベースを構築した。